Outils IA pour la recherche
RETEX après 2 ans d’utilisation
2026-05-05
Mon interêt pour les outils IA
- Intérêt croissant depuis 2023 suite à un stage chez les Pompiers de Paris
- Utilisation régulière depuis 2024
- Codex, Copilot, Claude Code, NotebookLM, etc.
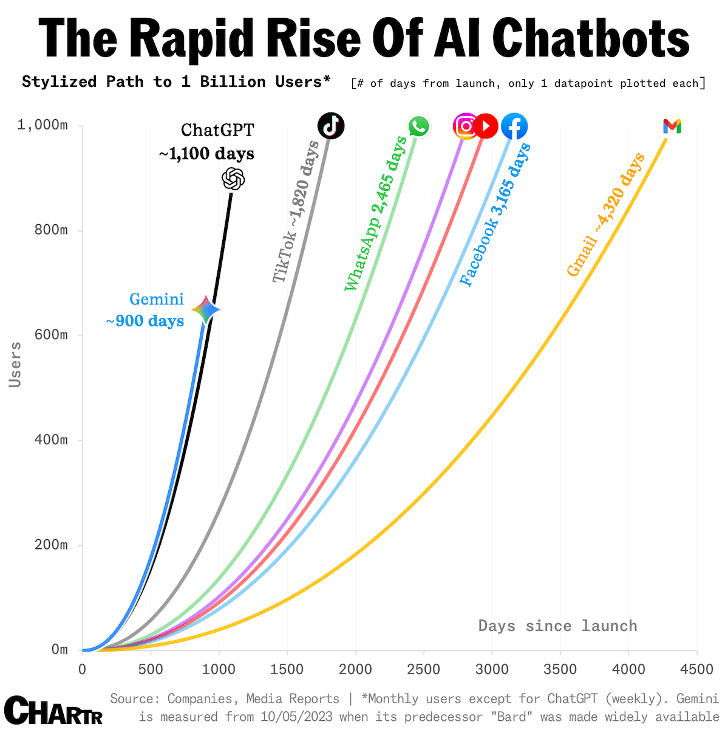

Pourquoi ce talk?
Pain points
- Trop de papiers, pas assez de temps pour faire le tri
- Un bug de code caché dans 10k lignes de code
- Idée claire sous la douche, floue au clavier
- TikZ est un maître cruel et impitoyable
Promesse honête
- IA ne remplacera pas le jugement
- IA ne prouvera pas votre théorème (encore) (Axiom Math 2026)
- IA peut enlever une énorme friction

Tour de table : Quels outils ? Quels usages ?
- Quels outils IA utilisez-vous déjà ?
- Quels usages vous intéressent le plus ?

Imaginez les outils d’agents IA comme un chercheur junior avec une énergie infinie, zéro honte, et une fiabilité inégale.
Qu’est-ce qu’un LLM (1) ?
Un LLM (Large Language Model) est un modèle entraîné sur une quantité pharaonique de texte et de code pour prédire le prochain token \(P(\text{token}_t\mid \text{token}_{<t})\) :
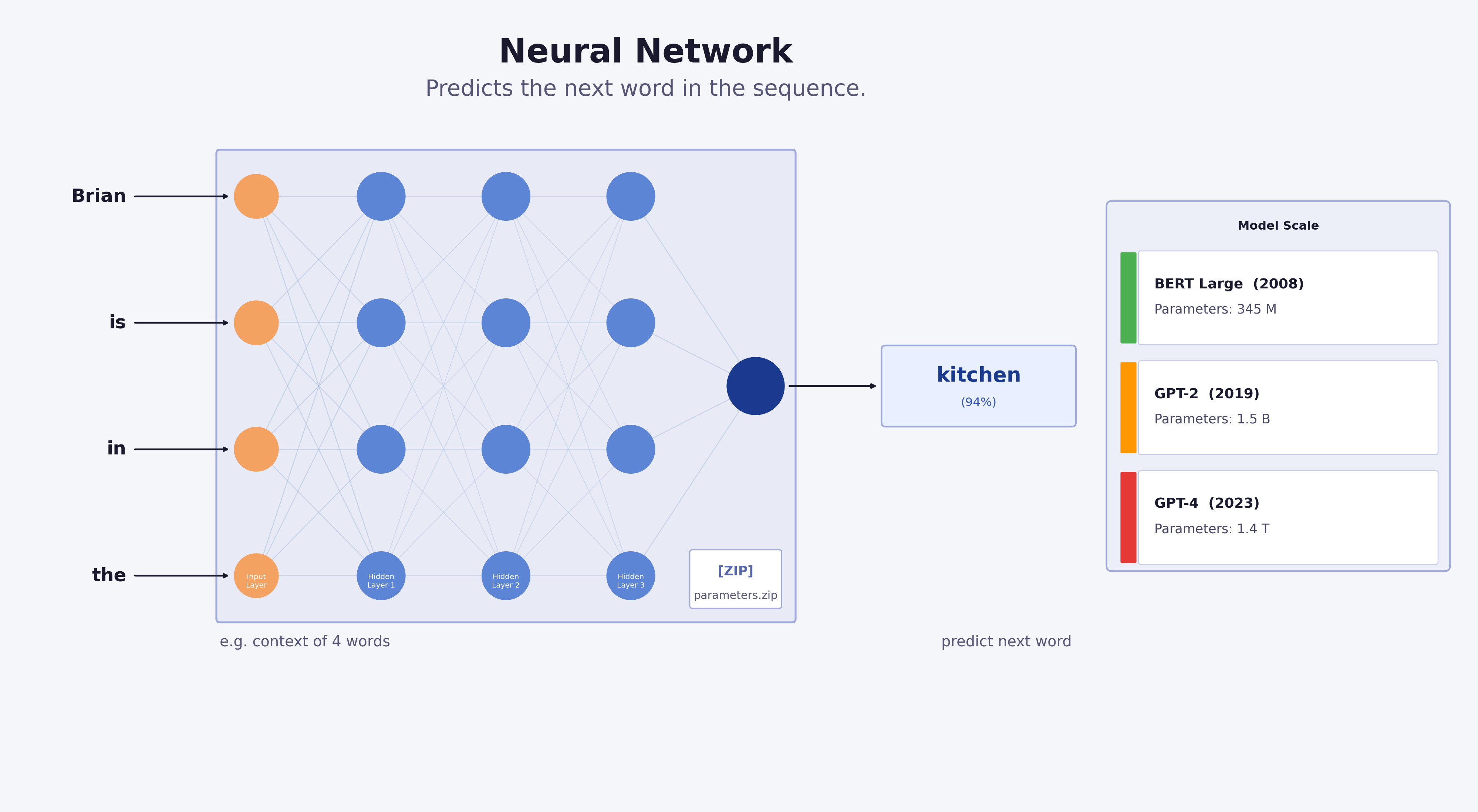
Qu’est-ce qu’un LLM (2) ?
Qu’est-ce que ça veut dire en pratique?
- Machines à faire de la complétion de texte.
- PAS des bases de données, ni des garanties de vérité (OpenAI 2025).
- Vachement utile quand ils sont connectés à des outils (fichiers, code, recherche, tests).
- Prompt précis -> Meilleurs résultats
Chat mode vs Agent mode
Chat mode
- Un prompt -> une réponse
- Idéal pour explications et brainstorming
- Exemple : “Expliquez Gibbs-Thomson en termes simples.”
Agent mode
- Lire fichiers/docs, éditer du code, exécuter des tests, patch
- Exemple pour le codage : “Scan repo, implement a new function, keep API, add tests.”
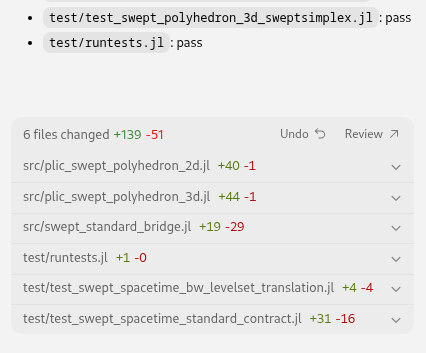
Tour d’horizon des outils disponibles

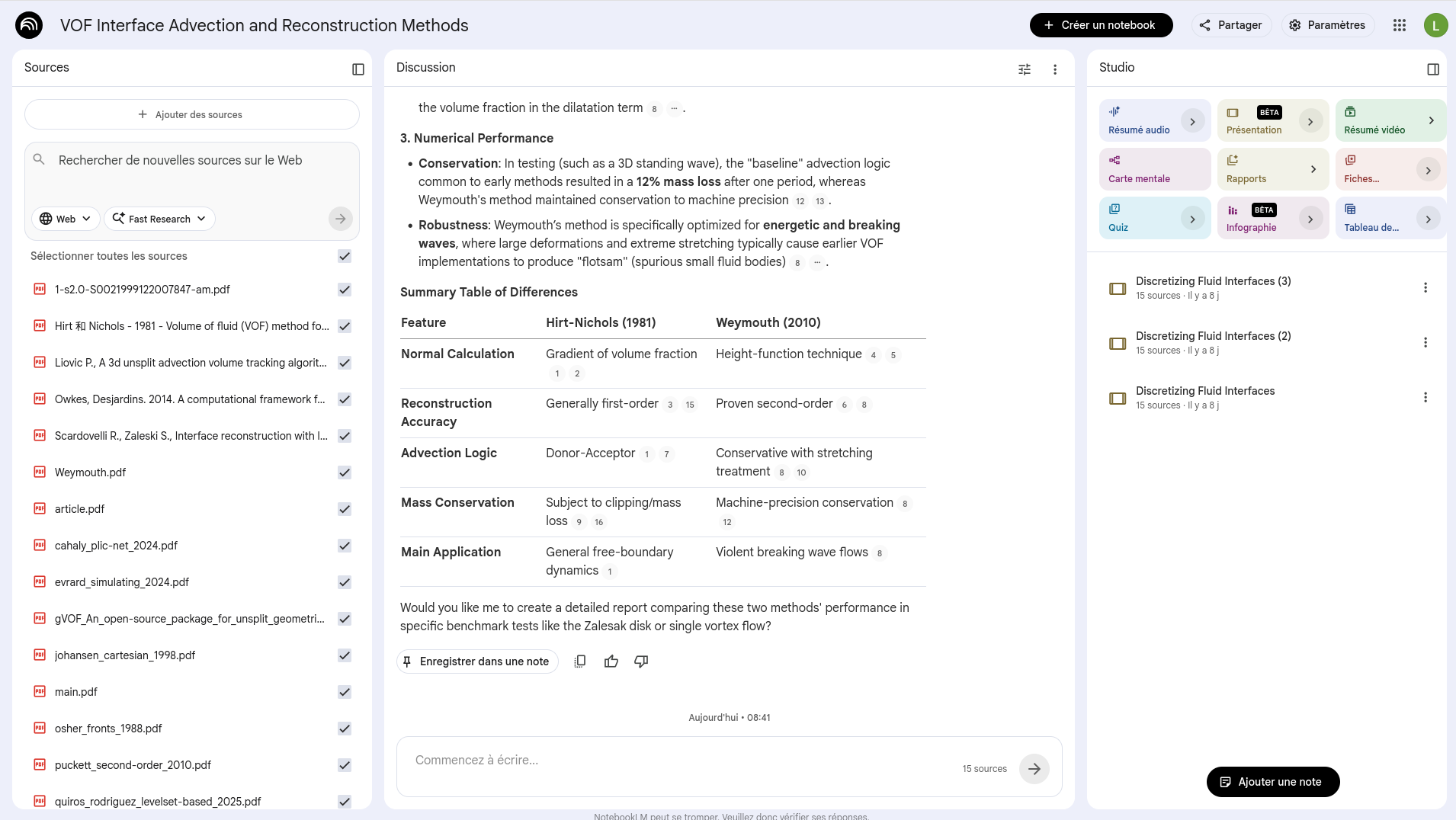
Activité 1: NotebookLM pour la revue de littérature et plus
NotebookLM (Google) permet de télécharger des documents et de poser des questions à leur sujet. Il peut être utilisé pour la revue de littérature, la synthèse, et plus encore.
URL : NotebookLM
Pourquoi on atteint les limites ?
- Cache misses
- Context bloat
- Mauvais modèle / mauvais effort
- Mauvais format d’entrée

Le vrai levier : protéger le préfixe caché
- Choisir outils/MCP au début
- Choisir modèle au début
- Ne pas changer
/modelen cours - Garder
AGENTS.md/CLAUDE.mdcourts - Déplacer le détail vers
MATH.md,TESTING.md,SKILL.md

Hygiène de session
/clearentre deux sujets/compactaprès une tâche ou vers 50–80%/rewindsi la session part mal- Subagents pour lecture massive, logs, PDF, recherche fichiers
Ne laissez pas l’agent relire votre repo entier à chaque question.

Choisir le bon modèle
- Petit modèle : grep, renommage, formatage
- Moyen modèle : exploration code, tests, synthèse locale
- Gros modèle : architecture, compromis numériques
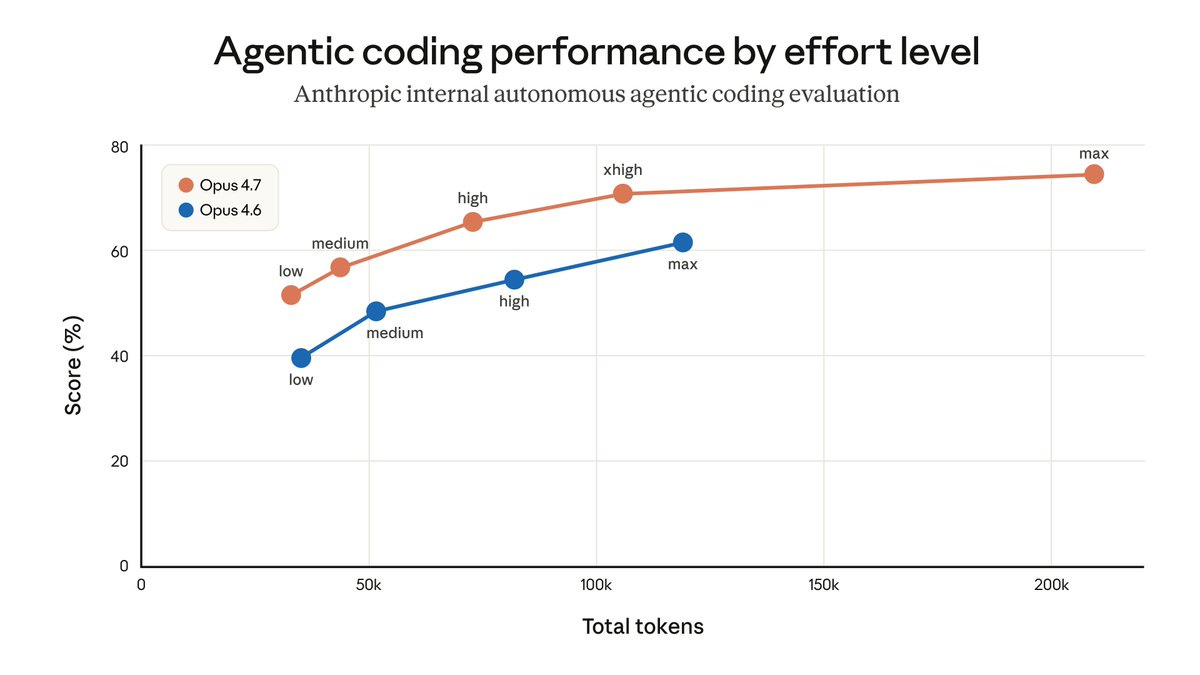
L’effort se règle par prompt.
Mauvais format = tokens brûlés
- Web : texte / accessibility tree plutôt que screenshots
- PDF :
pdftotextavant images - Gros repo : carte de code / graphe plutôt que lecture brute
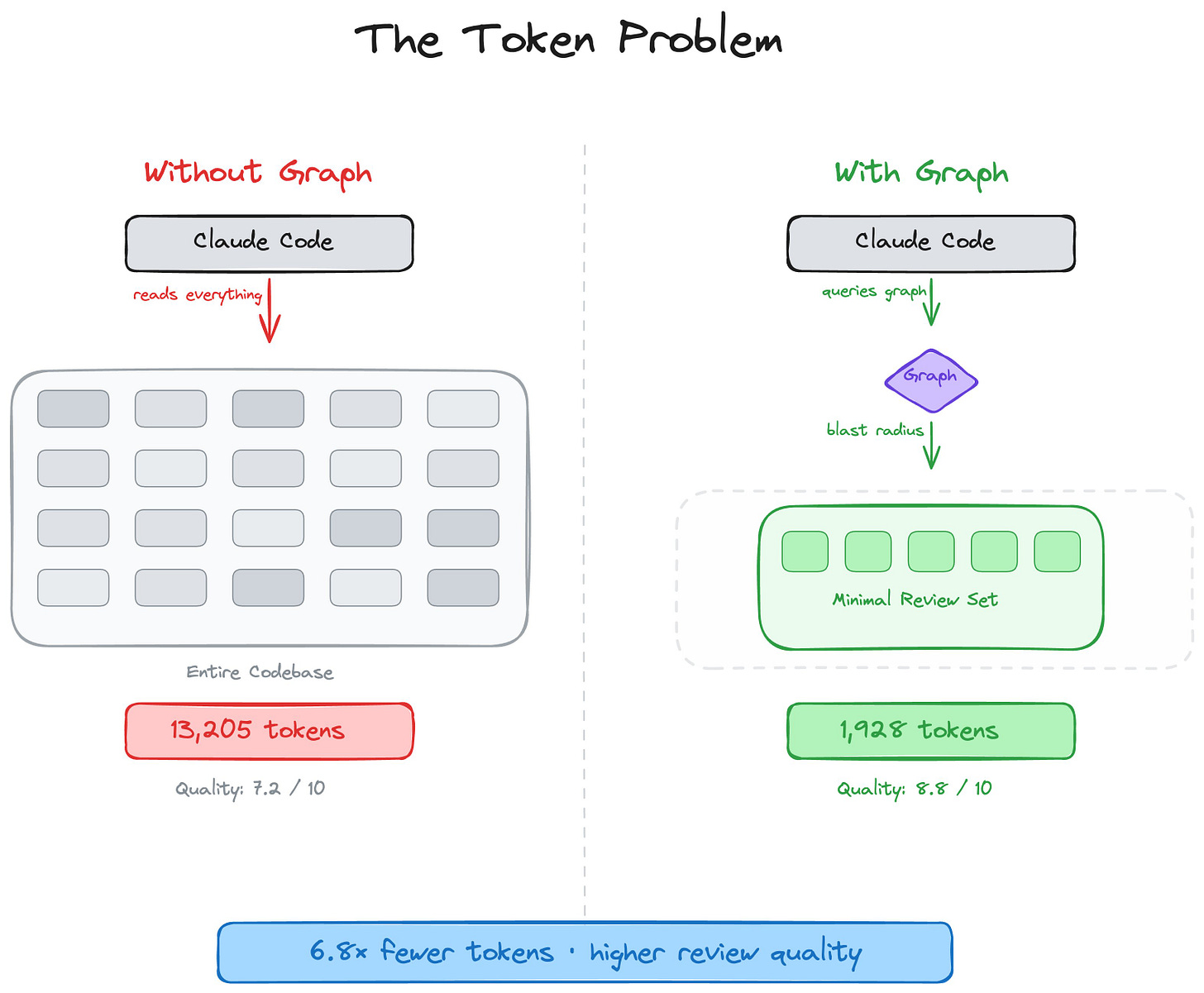
Activité 3: Gestion de la mémoire des projets
- Problème : Faible mémoire à long term des LLMs
- ex : 400k tokens pour Codex 5.3 High
- Solution : Fichiers de projet (
AGENTS.md,MATH.md,SKILL.md) pour stocker les faits, règles, théorèmes, procédures - Solution : LLMWiki + Obsidian pour une mémoire de projet plus riche et interconnectée
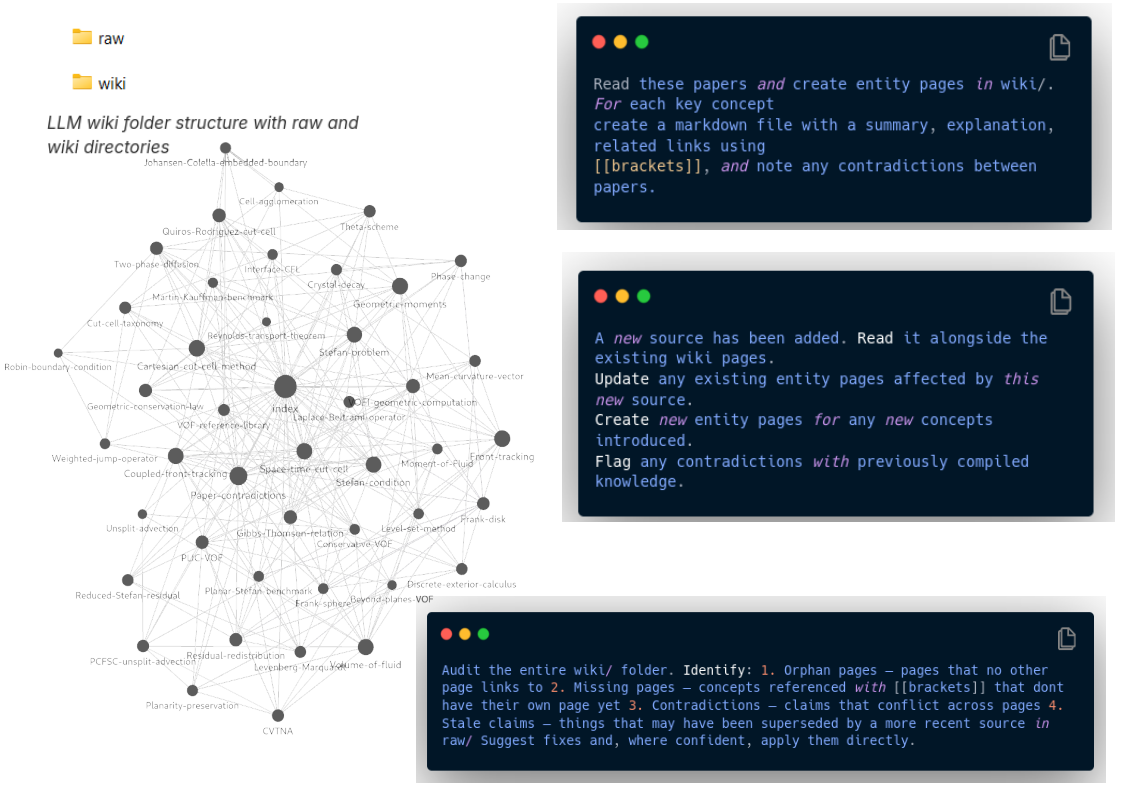
Quelques points clés
- Notion de Context Window
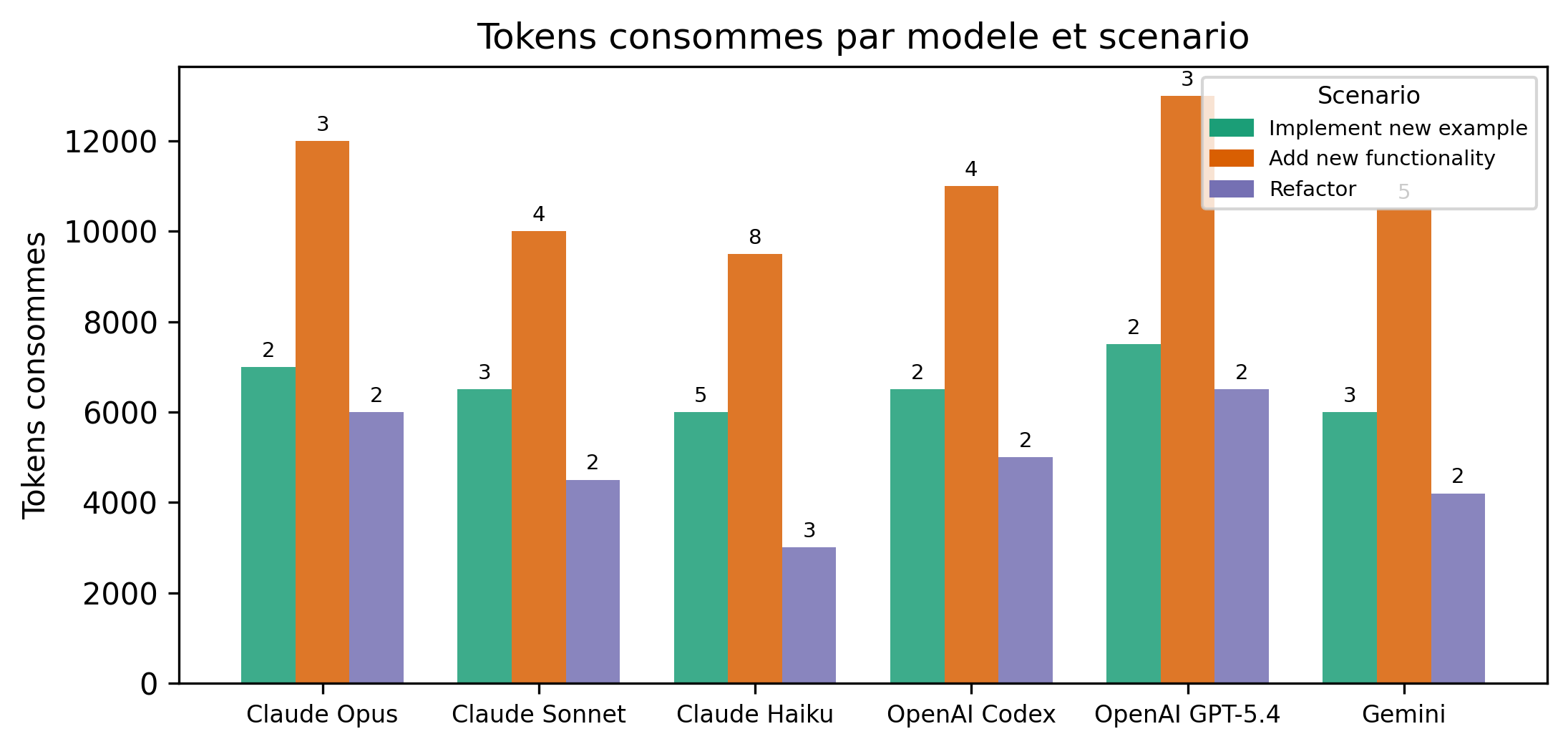
- Taille des modeles et coût : choisir le bon outil pour la bonne tâche
- De l’importance du prompt pour guider les agents
- Validation humaine indispensable pour éviter les erreurs et les “hallucinations”
